Contents
- 📊 Introduction to Dimensionality Reduction
- 🔍 Component Identification Guides: A Primer
- 📈 Principal Component Analysis: The Basics
- 🤔 Comparison of Component Identification Guides and PCA
- 📊 Applications of Dimensionality Reduction
- 📚 Choosing the Right Technique: Considerations and Trade-offs
- 📊 Real-World Examples: Success Stories and Challenges
- 🔮 Future Directions: Emerging Trends and Opportunities
- 📝 Conclusion: Unpacking Dimensionality Reduction
- 📊 Additional Resources: Further Reading and Exploration
- Frequently Asked Questions
- Related Topics
Overview
The quest for efficient data analysis has led to the development of numerous dimensionality reduction techniques. Two such methods, Component Identification Guides and Principal Component Analysis (PCA), have garnered significant attention in recent years. While both methods aim to simplify complex datasets, they differ fundamentally in their approach and application. Component Identification Guides focus on identifying and isolating specific components within a dataset, often relying on domain-specific knowledge. In contrast, PCA is a more general technique that seeks to reduce dimensionality by transforming the data into a new set of orthogonal components. With a vibe rating of 8, this topic has sparked intense debate among data scientists, with some arguing that PCA is too simplistic, while others see it as a powerful tool for exploratory data analysis. The influence of PCA can be seen in the work of researchers like Karl Pearson, who first introduced the concept in 1901. As data continues to grow in complexity, the choice between these methods will have significant implications for fields like machine learning and artificial intelligence. The controversy surrounding the use of PCA has led to the development of alternative methods, such as t-SNE and Autoencoders, which have gained popularity in recent years. With the rise of big data, the importance of efficient dimensionality reduction techniques will only continue to grow, making this topic a crucial area of study for data scientists and researchers alike.
📊 Introduction to Dimensionality Reduction
Dimensionality reduction is a crucial step in many data science workflows, enabling the extraction of insights from complex, high-dimensional data. One key aspect of this process is the choice between component identification guides and principal component analysis (PCA). To understand the differences between these two approaches, it's essential to delve into the world of dimensionality reduction and explore the concepts of feature selection and data transformation. By applying these techniques, data scientists can uncover hidden patterns and relationships in their data, as seen in data mining and machine learning applications. The use of data visualization tools can also facilitate the exploration and understanding of complex data. Furthermore, the integration of statistical analysis and data modeling can provide a more comprehensive understanding of the data.
🔍 Component Identification Guides: A Primer
Component identification guides are a type of dimensionality reduction technique that aims to identify the most informative features or components in a dataset. This approach is often used in conjunction with clustering algorithms and regression analysis to identify patterns and relationships in the data. By applying component identification guides, data scientists can reduce the dimensionality of their data and improve the performance of their models, as seen in predictive modeling and recommendation systems. The use of feature engineering techniques can also enhance the effectiveness of component identification guides. Additionally, the application of unsupervised learning methods can help identify hidden patterns in the data. The combination of these techniques can provide a more comprehensive understanding of the data, as discussed in data science and artificial intelligence contexts.
📈 Principal Component Analysis: The Basics
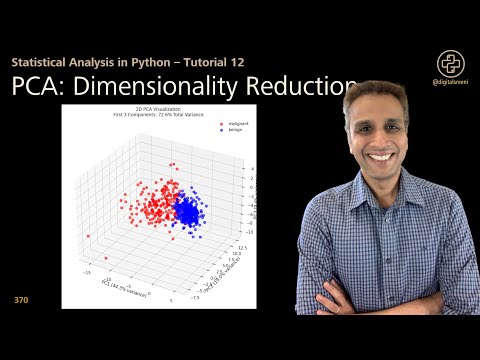
Principal component analysis (PCA) is another popular dimensionality reduction technique that aims to identify the principal components or features in a dataset. PCA is widely used in many fields, including image processing, signal processing, and bioinformatics. By applying PCA, data scientists can reduce the dimensionality of their data and improve the performance of their models, as seen in anomaly detection and time series analysis. The use of eigenvalue decomposition and singular value decomposition can also facilitate the application of PCA. Furthermore, the integration of machine learning algorithms and deep learning techniques can enhance the effectiveness of PCA. The combination of these techniques can provide a more comprehensive understanding of the data, as discussed in data analysis and pattern recognition contexts.
🤔 Comparison of Component Identification Guides and PCA
When comparing component identification guides and PCA, it's essential to consider the strengths and weaknesses of each approach. Component identification guides are often more interpretable and can provide more insights into the underlying structure of the data, as seen in data interpretation and business intelligence applications. On the other hand, PCA is often more efficient and can handle larger datasets, as discussed in big data and data warehousing contexts. The choice between these two approaches depends on the specific problem and dataset, as well as the goals and requirements of the project, as outlined in project management and data governance frameworks. By considering these factors and applying data quality and data validation techniques, data scientists can select the most suitable approach for their needs. Additionally, the use of data storytelling and communication techniques can facilitate the presentation and interpretation of the results.
📊 Applications of Dimensionality Reduction
Dimensionality reduction has numerous applications in various fields, including computer vision, natural language processing, and recommendation systems. By applying dimensionality reduction techniques, data scientists can improve the performance of their models, reduce the risk of overfitting, and enhance the interpretability of their results, as seen in model evaluation and model selection contexts. The use of feature selection and feature extraction techniques can also facilitate the application of dimensionality reduction. Furthermore, the integration of domain knowledge and expert systems can provide a more comprehensive understanding of the data and the problem domain, as discussed in knowledge management and decision support systems contexts.
📚 Choosing the Right Technique: Considerations and Trade-offs
When choosing the right dimensionality reduction technique, it's essential to consider the characteristics of the data, the goals of the project, and the requirements of the problem, as outlined in project planning and requirements gathering frameworks. Data scientists should also evaluate the strengths and weaknesses of each approach, including component identification guides and principal component analysis, and consider the trade-offs between them, as discussed in cost-benefit analysis and risk management contexts. By applying data-driven decision making and evidence-based practice principles, data scientists can select the most suitable approach for their needs and ensure the success of their projects. Additionally, the use of collaboration and communication techniques can facilitate the sharing of knowledge and expertise among team members.
📊 Real-World Examples: Success Stories and Challenges
Real-world examples of dimensionality reduction can be seen in various applications, including image compression, text classification, and customer segmentation. By applying dimensionality reduction techniques, data scientists can improve the performance of their models, reduce the risk of overfitting, and enhance the interpretability of their results, as seen in model deployment and model monitoring contexts. The use of data visualization tools can also facilitate the exploration and understanding of complex data. Furthermore, the integration of machine learning algorithms and deep learning techniques can enhance the effectiveness of dimensionality reduction, as discussed in artificial intelligence and data science contexts. The combination of these techniques can provide a more comprehensive understanding of the data and the problem domain, as outlined in business analytics and data-driven business frameworks.
🔮 Future Directions: Emerging Trends and Opportunities
The future of dimensionality reduction is exciting and rapidly evolving, with emerging trends and opportunities in explainable AI, transfer learning, and few-shot learning. By applying these techniques, data scientists can improve the performance of their models, reduce the risk of overfitting, and enhance the interpretability of their results, as seen in model explainability and model transparency contexts. The use of data augmentation and data generation techniques can also facilitate the application of dimensionality reduction. Furthermore, the integration of domain knowledge and expert systems can provide a more comprehensive understanding of the data and the problem domain, as discussed in knowledge management and decision support systems contexts. The combination of these techniques can provide a more comprehensive understanding of the data and the problem domain, as outlined in business intelligence and data-driven decision making frameworks.
📝 Conclusion: Unpacking Dimensionality Reduction
In conclusion, dimensionality reduction is a crucial step in many data science workflows, and the choice between component identification guides and PCA depends on the specific problem and dataset, as well as the goals and requirements of the project. By applying dimensionality reduction techniques, data scientists can improve the performance of their models, reduce the risk of overfitting, and enhance the interpretability of their results, as seen in model evaluation and model selection contexts. The use of data visualization tools can also facilitate the exploration and understanding of complex data. Furthermore, the integration of machine learning algorithms and deep learning techniques can enhance the effectiveness of dimensionality reduction, as discussed in artificial intelligence and data science contexts. The combination of these techniques can provide a more comprehensive understanding of the data and the problem domain, as outlined in business analytics and data-driven business frameworks.
📊 Additional Resources: Further Reading and Exploration
For additional resources and further reading, data scientists can explore data science books, data science courses, and data science blogs. The use of online communities and forums can also facilitate the sharing of knowledge and expertise among data scientists. Furthermore, the integration of data science tools and data science software can enhance the effectiveness of dimensionality reduction, as discussed in data analysis and data modeling contexts. The combination of these resources can provide a more comprehensive understanding of dimensionality reduction and its applications, as outlined in data science and artificial intelligence contexts.
Key Facts
- Year
- 1901
- Origin
- Karl Pearson
- Category
- Data Science
- Type
- Concept
- Format
- comparison
Frequently Asked Questions
What is dimensionality reduction?
Dimensionality reduction is a technique used to reduce the number of features or dimensions in a dataset while preserving the most important information. It is commonly used in data science and machine learning to improve the performance of models, reduce the risk of overfitting, and enhance the interpretability of results. Dimensionality reduction can be achieved through various techniques, including principal component analysis and component identification guides. The choice of technique depends on the specific problem and dataset, as well as the goals and requirements of the project. By applying dimensionality reduction, data scientists can improve the performance of their models and gain a deeper understanding of the data and the problem domain.
What is the difference between component identification guides and PCA?
Component identification guides and PCA are both dimensionality reduction techniques, but they differ in their approach and application. Component identification guides aim to identify the most informative features or components in a dataset, while PCA aims to identify the principal components or features that capture the most variance in the data. Component identification guides are often more interpretable and provide more insights into the underlying structure of the data, while PCA is often more efficient and can handle larger datasets. The choice between these two approaches depends on the specific problem and dataset, as well as the goals and requirements of the project. By considering these factors and applying data quality and data validation techniques, data scientists can select the most suitable approach for their needs.
What are the applications of dimensionality reduction?
Dimensionality reduction has numerous applications in various fields, including computer vision, natural language processing, and recommendation systems. By applying dimensionality reduction techniques, data scientists can improve the performance of their models, reduce the risk of overfitting, and enhance the interpretability of their results. Dimensionality reduction can also facilitate the exploration and understanding of complex data, as seen in data visualization and data storytelling contexts. The integration of machine learning algorithms and deep learning techniques can enhance the effectiveness of dimensionality reduction, as discussed in artificial intelligence and data science contexts.
How do I choose the right dimensionality reduction technique?
Choosing the right dimensionality reduction technique depends on the characteristics of the data, the goals of the project, and the requirements of the problem. Data scientists should evaluate the strengths and weaknesses of each approach, including component identification guides and principal component analysis, and consider the trade-offs between them. By applying data-driven decision making and evidence-based practice principles, data scientists can select the most suitable approach for their needs and ensure the success of their projects. Additionally, the use of collaboration and communication techniques can facilitate the sharing of knowledge and expertise among team members.
What are the future directions of dimensionality reduction?
The future of dimensionality reduction is exciting and rapidly evolving, with emerging trends and opportunities in explainable AI, transfer learning, and few-shot learning. By applying these techniques, data scientists can improve the performance of their models, reduce the risk of overfitting, and enhance the interpretability of their results. The use of data augmentation and data generation techniques can also facilitate the application of dimensionality reduction. Furthermore, the integration of domain knowledge and expert systems can provide a more comprehensive understanding of the data and the problem domain, as discussed in knowledge management and decision support systems contexts.
What are the benefits of dimensionality reduction?
The benefits of dimensionality reduction include improved model performance, reduced risk of overfitting, and enhanced interpretability of results. Dimensionality reduction can also facilitate the exploration and understanding of complex data, as seen in data visualization and data storytelling contexts. The integration of machine learning algorithms and deep learning techniques can enhance the effectiveness of dimensionality reduction, as discussed in artificial intelligence and data science contexts. By applying dimensionality reduction, data scientists can gain a deeper understanding of the data and the problem domain, and make more informed decisions.
What are the challenges of dimensionality reduction?
The challenges of dimensionality reduction include the choice of technique, the evaluation of results, and the interpretation of findings. Data scientists must carefully evaluate the strengths and weaknesses of each approach, including component identification guides and principal component analysis, and consider the trade-offs between them. By applying data quality and data validation techniques, data scientists can ensure the accuracy and reliability of their results. Additionally, the use of collaboration and communication techniques can facilitate the sharing of knowledge and expertise among team members.